One hundred development sprints, that’s a nice rounded number… and a good moment to rethink the way we write and publish our reports.
Yes, you read it right. This post will be the last one following our traditional format, assuming something can already be called “traditional” after four and a half years. As we will explain at the end of this post, subsequent reports will look more as a digest with links to information and not that much as a traditional blog post that tries to tell a story.
But the Age of the Digest has not come yet. Let’s close the Age of the Stories with a last blog post covering several topics:
- A better editor for the
<partitioning>section of AutoYaST - Improved YaST support for advanced LVM and Btrfs features
- Ensuring YaST is not left behind in the migration to
/usr/etc - Taking XML processing in YaST to the next level
Many of those topic are clearly oriented into the mid-term future and, as such, it will take some time until they reach stable versions of openSUSE Leap or SUSE Linux Enterprise. Unless told otherwise, the changes described in this post will only be visible in the short term for openSUSE Tumbleweed users.
AutoYaST UI: Improve Editing Drives
Let’s start with an exception to the rule just mentioned. That is, something many users will see soon in their systems, since we plan to release it as a maintenance update for both 15.1 and 15.2 and the corresponding SLE versions.
As part of the initiative to modernize AutoYaST, the user interface for creating or editing the profile’s partitioning section has been finally revamped. That means no more missing storage features such as Bcache, RAIDs, Btrfs multi-device file systems, etc.
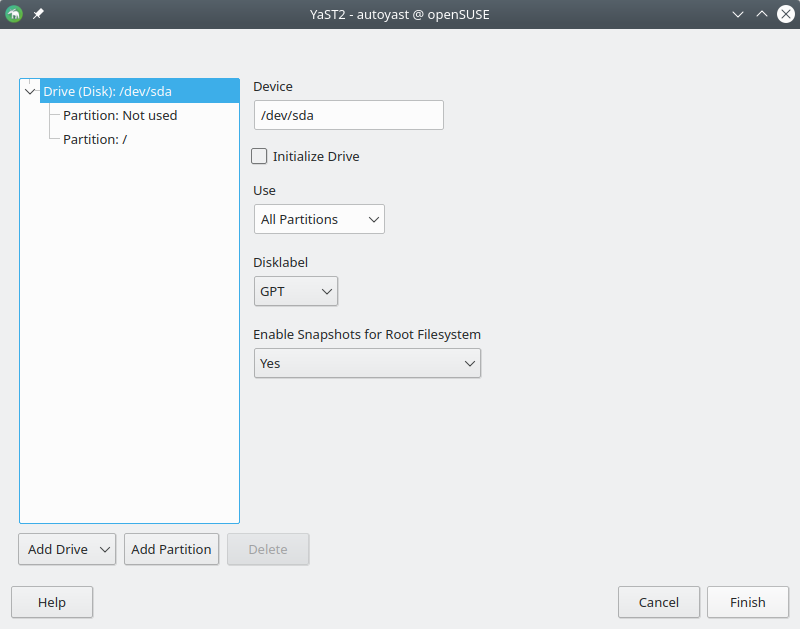
Apart from allowing to set every supported attribute by the AutoYaST partitioning section, during the rewrite we tried to keep the module as simple as possible to easy the user interaction, not only distributing the fields to put related stuff together and not having a crammed interface but also avoiding warnings and confirmation popup for each change done.

Of course, there is room for improvement yet, but at least we did the first step getting rid of the complex and broken old UI to start working in a simpler one.
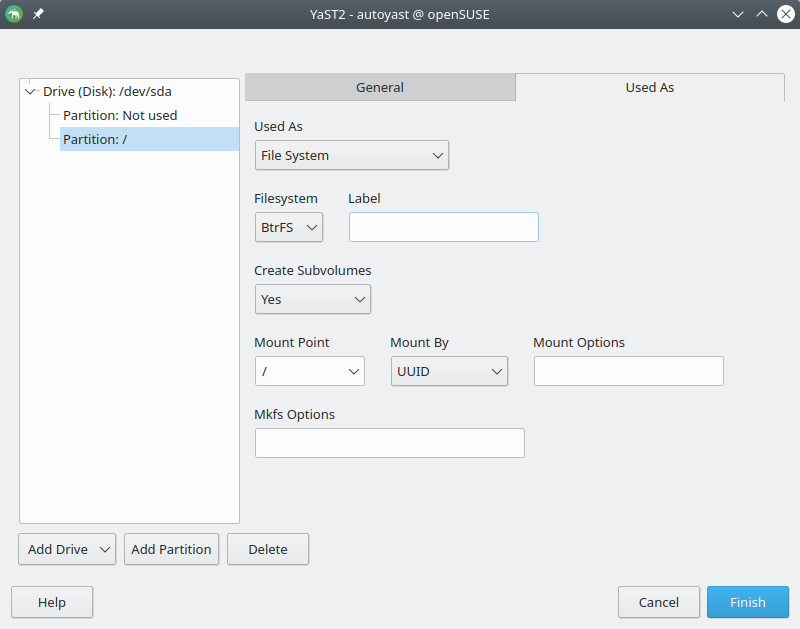
Recognizing LVM Advanced Features
As you know, YaST can be used to configure storage setups combining several technologies like MD RAID, bcache, Btrfs and LVM. Not every single feature of each one of those technologies can be tweaked using YaST, since would lead to a completely unmanegable interface and a hardly predictable behavior.
But even if YaST cannot create certain advanced configurations, it should be able to recognize them, display them in the interface and allow simple modifications.
In the last couple of sprints we have focused in teaching YaST how to deal with advanced LVM features. Now it is able to detect and use LVM RAID, mirror logical volumes and LVM snapshots, both thick and thin ones.
YaST does not allow to create such setups and we don’t plan to support that in a foreseable future. But users that already use those LVM features will now be able to use YaST for some operations and to have a more complete and accurate picture of their storage configuration. In addition, the partial support for such technologies makes easier the upgrade process for systems using them.
Probing Btrfs Snapshot Relations and Two Peculiarities
On a purely technical level, all the additions explained above imply adding new possibilities to the so-called devicegraph which is used by libstorage-ng to represent any system. That included representing the LVM snapshots and the relations between origins and snapshots. That being done, it should be easy enough to go one step further and also recognize and represent those relations for btrfs subvolumes… except for two peculiarities.
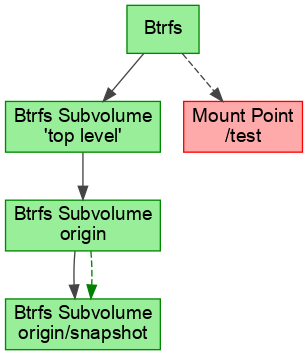
The first one is that a btrfs snapshot can be both the child and the snapshot of the same subvolume. Suppose we have a btrfs mounted at /test. First we create a subvolume and then a snapshot of it:
cd /test
btrfs subvolume create origin
btrfs subvolume snapshot origin origin/snapshot
Now “snapshot” is a child of “origin” since it is placed directly under “origin” in the directory structure. In the devicegraph this means we have parallel edges (the gray for the child and the green for the snapshot):
The second peculiarity comes from the freedom of btrfs to rename and move subvolumes. We can move “origin” under “snapshot”:
mv origin/snapshot .
mv origin snapshot
The resulting devicegraph has a cycle:
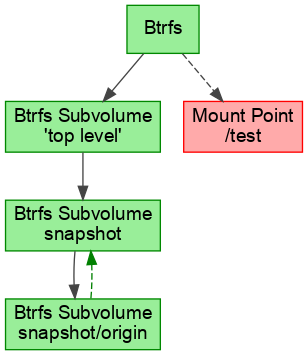
So far that could not happen and some algorithms assumed that the devicegraph is always a directed acyclic graph (DAG). To remedy those algorithms we let them operate on a filtered devicegraph that hides the snapshot relations. Those filters were also added lately to libstorage-ng for LVM snapshots.
Now that libstorage-ng contains the mechanisms to deal with all these circumstances, we can think about offering advanced Btrfs options in YaST. But that will take some time since it comes with some challenges, with the design of the interface not being exactly the smallest one. Meanwhile, you can play around with this new libstorage-ng feature using the “probe” command included in the package “libstorage-ng-utils”, as long as you enable the experimental feature with the new variable “YAST_BTRFS_SNAPSHOT_RELATIONS”.
YAST_BTRFS_SNAPSHOT_RELATIONS=yes /usr/lib/libstorage-ng/utils/probe --display
Automatic Check for New /usr/etc/ Files
As we have already mentioned in previous
reports,
more and more parts of the distribution are changing the way they organize their
configuration files. Things are moving from single configuration files in
/etc to a layered structure that starts at /usr/etc and includes multiple
files with different orders of precedence.
The YaST developers need to know when a file location is changed so we could
adapt YaST to read and write to the correct location. Otherwise it could easily
happen that the YaST changes would be ignored and we would get bug reports
later. Therefore we implemented a regular check which scans for all etc
configuration files in Tumbleweed and reports new unknown files.
The script is run once a week automatically at Travis. It downloads the repository metadata file which contains a list of files from all packages. It also contains files which are marked as “ghost”, these files are not part of the package but might be created by RPM post-install script or by user. We just compare the found files with a known list.
Some implementation details of that script may be interesting for our more
technical readers, since it uncompresses a *.xml.gz file and parses the XML on
the fly while downloading. That means it does not need to temporarily save the
file to disk or need it loaded whole in memory. That is really important in this
case because the unpacked XML is really huge, it has more than 650MB!
Improvements in YaST’s XML Parser
And talking about technical details, you may remember a couple of sprints ago we mentioned we had started a small side project to improve YaST’s XML parser. Now we can report significant progress on that front.
Let’s first clarify that we are not trying to re-invent the wheel by writing just another low-level parser to deal with XML internals. We are relying on existing parsers to rethink the way YaST serializes data into XML and back. All that with the following goals:
- Ensuring consistency of information when data is transformed into XML and then into raw data again, with our previous tools some information got silently lost in translation.
- Report accurate errors if something goes wrong during the mentioned transformation, so we know whether we can trust the result.
- Possibility of validating the XML at an early stage of (Auto)YaST execution.
- Reduce the amount of code we need to maintain.
- Make hand writting of XML easier.
We wrote quite some details about how we are achieving each one of those goals just to realize all that fits better into a separate dedicated blog post. Stay tuned if you are interested in those technical details. If you are not, you may be wondering how all this affects you as a final user. So far, the advantages will be specially noticeable for AutoYaST users. More consistent and shorter XML enables easier editing of the AutoYaST profile. Schema validation allows early warning when the XML is malformed. And the more precise error reporting will prevent silent failures caused by errors in the AutoYaST profile that can lead to subsequent problems in the system.
We keep moving
The future will not only bring a better AutoYaST, more LVM and Btrfs capabilities or a new XML parser. As mentioned at the beginning of this post, we will also change a bit the way we communicate the changes implemented in every YaST development sprint.
We currently invest quite some effort every two weeks putting all the information together in the form of a text that can be read as a consistent and self-contained nice story, and that is not always that easy. We feel time has come to try an alternative approach.
From now on, our sprint reports will consist basically in a curated and organized list of links to pull requests at Github. On one hand, the YaST Team puts a lot of effort into writing comprehensive and didactic descriptions for each pull request. On the other hand, our readers are usually more interested in some particular topics than in others. So we feel such digest will provide a good overview allowing the readers to focus on some topics by checking the descriptions of the corresponding pull requests.
We will still publish those summaries in this blog. And we will continue publishing occasional extra posts dedicated to a single topic, like the one about the revamped XML parser we just mentioned some lines above.
So, see you soon in this blog and in all our usual communication channels… and keep having a lot of fun!